
 189-7119-5501
189-7119-5501-

-

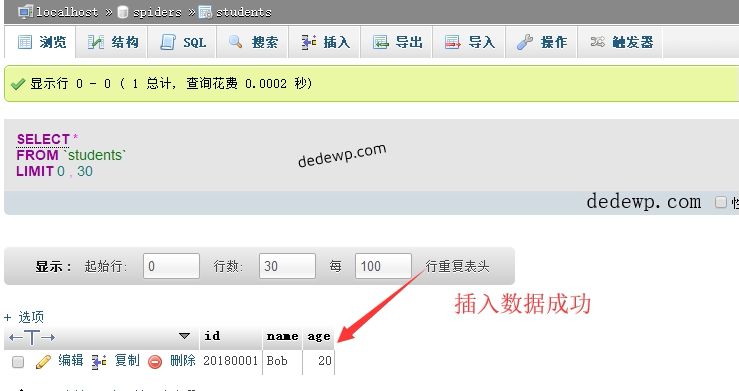
上一篇文章,我们已经成功通过python3连接到了数据库并新建了spiders数据库,今天我们就继续来学习python3如何创建mysql数据表及插入数据。 import pymysql db = pymysql.connect(host='localhost', user='root', password='r...
2018-04-27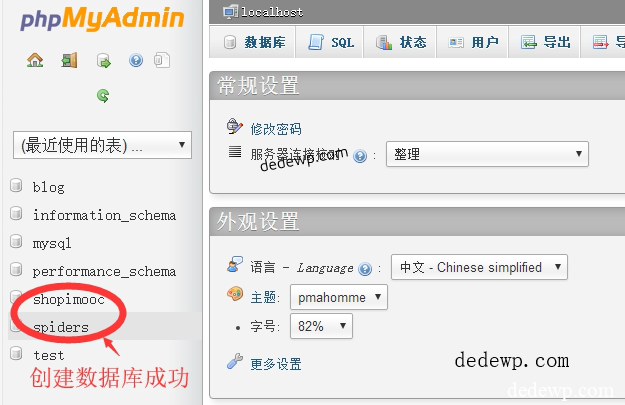
之前有教大家如何利用python3存储数据到excel,今天小雨在来教大家把数据存储到mysql数据库,毕竟mysql数据库大家经常使用,相信大家也期待了许久了吧! 第一步还是先安装模块:PyMySQL(不会安装的翻看之前的教程) 我们以本地mysql环境为例,不会安装的...
2018-04-27
学习python3,我们可以做一些有趣的事情,比如搞一个微信聊天机器人,配合图灵的接口就可以自high了。 首先我们需要安装itchat模块,这个在之前的教程讲过怎么通过pycharm安装模块,忘了的可以翻一翻历史文章。 然后就是去申请图灵的接口,免费的每天有100...
2018-03-27
之前python3文章中有if __name__ == '__main__'这个,很多初学者搞不懂,为啥要写这个呢,又是啥意思呢,今天小雨就用一篇文章来把这个东西讲透彻: 新建test.py文件,代码如下: # coding=utf-8 print('Python从入门到入魔') def main(): ...
2018-03-24
像小雨主要是玩Wordpress的,很多网站也需要登陆后才可以进行下一步操作,所以我们单独来讲一讲如何利用Python3模拟wordpress博客登陆 首先还是安装selenium模块,这在基础教程中已经说过如何一键安装了,就不重复演示了。 我们以火狐浏览器为例,需要先下...
2018-03-23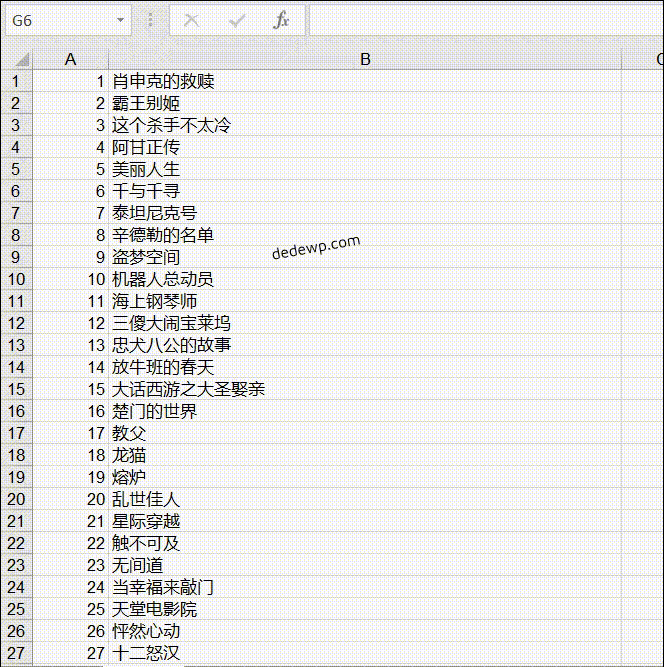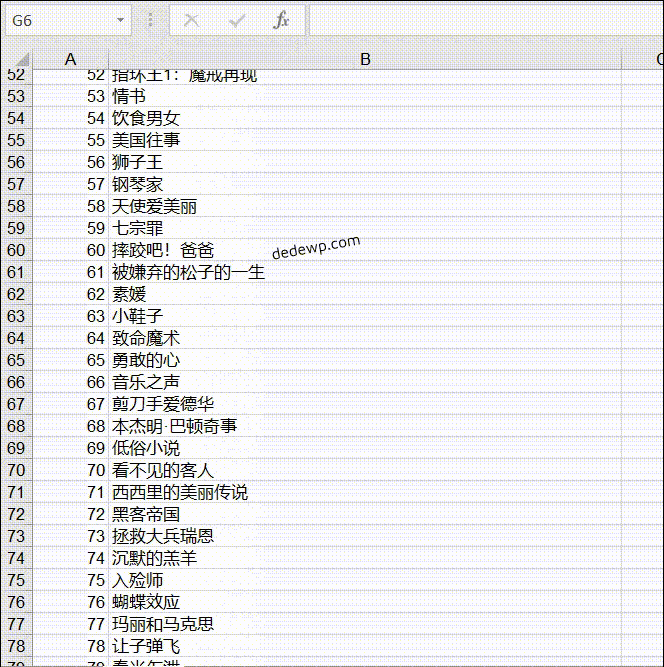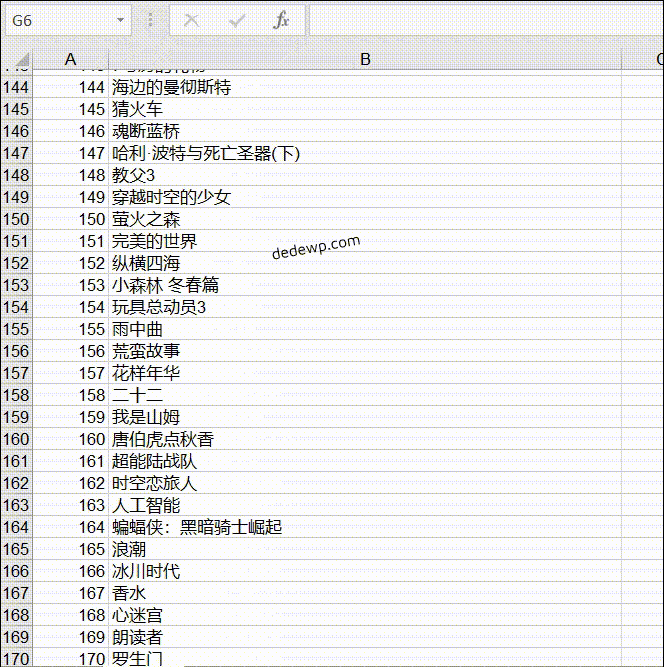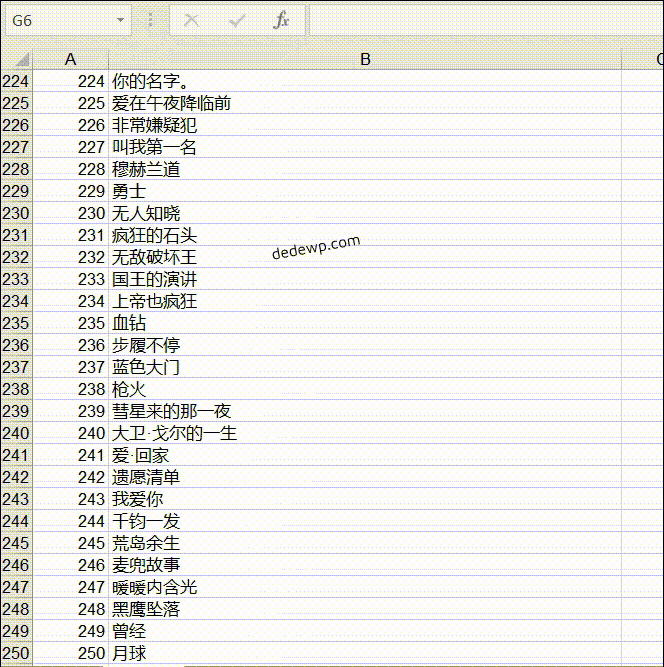
我们学习Python3爬虫的目的是为了获取数据,存储到本地然后进行下一步的作业,今天小雨就教大家python3如何将爬取的数据插入到Excel 我们直接来讲如何写入Excel文件: 基本流程就是:新建工作簿--新建工作表--插入数据--保存工作表,和我们在电脑上面操作e...
2018-03-22
很多人进群后不及时提交作业,不珍惜这个学习的机会,陌小雨就设置一些门槛,特此申明如下(2018-3-14): 很多初学python的朋友,苦于找不到一群志同道合的朋友,陌小雨给大家提供了一个平台,一个纯粹学习python的交流平台,274728691 这是陌小雨的QQ号...
2018-03-14
在python3爬虫利器Xpath:用Xpath提取文本这篇文章中,我们学会了用Xpath来提取网页中的文本,输出的格式是这样的 那么如何一行一个的输出呢? 这需要我们复习下小白教程中的列表和循环的章节,作为本次的第二个作业: 小雨给出了参考答案: ...
2018-03-14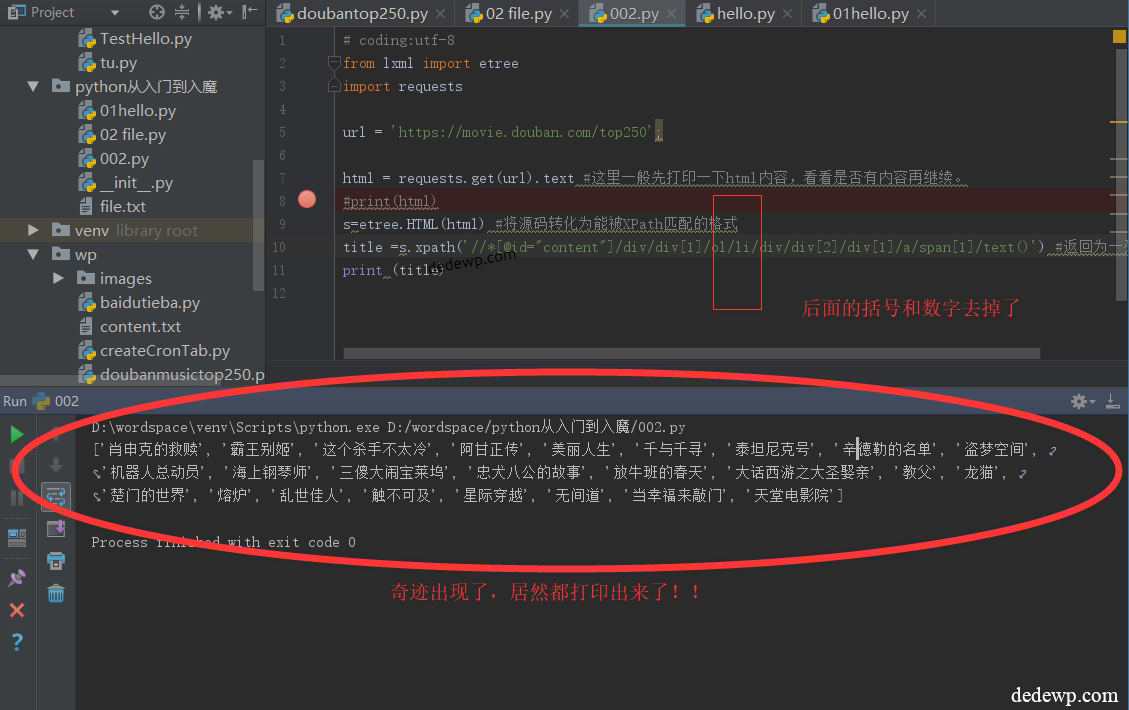
本篇文章需要前3篇文章的知识: Python3读取网页源代码我们用安装lxml库的方法来安装requests库,就可以用requests来读取网站的源代码了 [gzh2v keyword="9999" key="dedewp"] 还是以豆瓣电影top250为例:...Pycharm安装第三方库lxml还记得我们前...
2018-03-02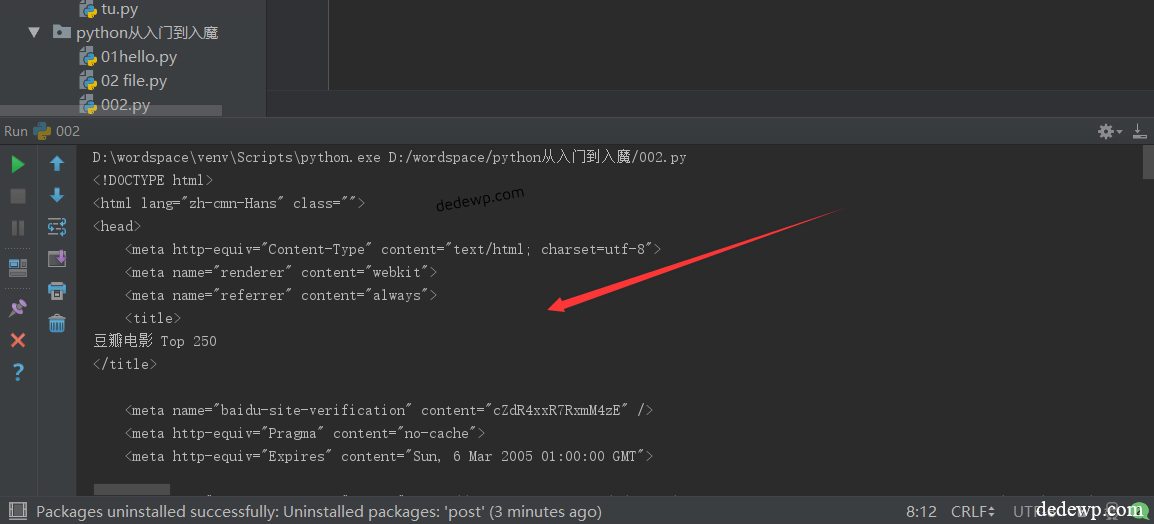
我们用安装lxml库的方法来安装requests库,就可以用requests来读取网站的源代码了 请输入验证码查看内容 验证码: 微信扫码,回复关键字“9999”获取验证码即可查看 ...
2018-03-02
