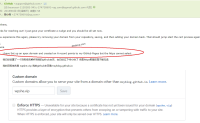
github pages是个不错选择,无限流量,无限空间,错误还有邮件提示,现在又支持了https,只需要花几块钱或者免费在万网领取(上面有幸运卷链接)一个域名,然后解析到github pages的二级域名就可以了,这里小雨具体分享一下如何成功设置这个https
如何在githu...
8年前 (2018-06-05) 5881℃
0喜欢
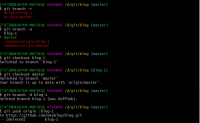
打开本地仓库,鼠标右键 选择Git Bash Here,输入下面代码创建分支blog-1
git branch blog-1
然后推送刚创建的分支到远程
git push origin blog-1
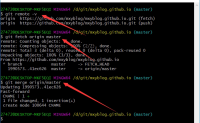
刷新一下就可以看到github上分支创建成功了。
查看本地分支
git ...
8年前 (2018-06-05) 6733℃
0喜欢
对于多办公环境,比如家里和办公室的电脑 有时候github线上的代码更新了,本地的还没有同步,首先就需要先把github上的代码下载到本地,使本地保持最新的状态。具体操作有一下几个步骤:
第一步:进入到本地仓库文件夹 鼠标右键 Git Bash Here,然后输入命令:$ gi...
8年前 (2018-06-03) 9094℃
0喜欢
在学习github过程中,难免会有很多次无效commits提交记录,如何删除这些commits记录呢?
最简单最粗暴的方法,自然是直接把仓库删了,然后重新建一个就完了。
当然了,这种方法并不适合所有场景,如果只是要删除指定commits后面所有的记录,我们可以通过下面两行命令来执...
8年前 (2018-05-31) 9753℃
0喜欢
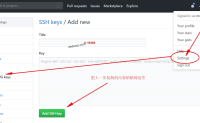
我们首先在本地电脑的新建一个文件夹,文件名任意,然后进入文件夹,鼠标右键选择Git Bash Here
然后输入命令:
ssh-keygen -t rsa -b 4096 -C"274728691@qq.com"
将邮箱替换为自己的github的邮箱,直接...
8年前 (2018-05-30) 10301℃
0喜欢
因为想折腾下小程序,所以陌小雨就得先把这个https弄好,产品服务随着时间会有所变化,所以小雨不敢保证今天分享的文章和攻略以后是不是一直有效,不过近期应该是没有问题的,本文分享的方案不需要手动申请免费的ssl证书,好了,跟着小雨一步一步的来操作吧。
首先需要购买CDN HTTP...
8年前 (2018-05-29) 7636℃
0喜欢
网上搜索的,记录一下,主要是通过判断浏览器的UA来进行区别
安卓QQ内置浏览器UA:
Mozilla/5.0 (Linux; Android 5.0; SM-N9100 Build/LRX21V) > AppleWebKit/537.36 (KHTML, like Geck...
8年前 (2018-05-27) 13617℃
0喜欢
为了方便理解,我们先来说一下大家常说的几个基本概念:
基本概念:
1、仓库 (Repository)简称Rep
仓库用来 存放 项目代码。 每个项目对应一个仓库。多个开源项目 则有多个仓库。
2、收藏 (star)
收藏项目 方便下次查看
3、克隆 复制(fork)
复制别人的仓...
8年前 (2018-05-27) 9701℃
0喜欢
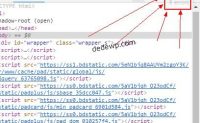
今天在给私人影院添加全网搜索功能的时候遇到一个小问题,在利用php正则匹配网页元素的时候,发现待匹配的网页中有两处代码差不多,不同的是其中一个元素的结尾都一样,如下图:
如何分别匹配出这两个
经过搜索和实践发现,正则匹配中有一个很强大的元字符
[^] 表示除中括号内原子之外的任...
8年前 (2018-05-24) 8871℃
0喜欢