我们学习Python3爬虫的目的是为了获取数据,存储到本地然后进行下一步的作业,今天小雨就教大家python3如何将爬取的数据插入到Excel
我们直接来讲如何写入Excel文件:
基本流程就是:新建工作簿–新建工作表–插入数据–保存工作表,和我们在电脑上面操作excel表是一样的。
workbook = xlwt.Workbook(encoding='utf-8')#创建workbook 即新建excel文件/工作簿,
worksheet = workbook.add_sheet('my_worksheet') #创建工作表,如果想创建多个工作表,直接在后面再add_sheet
worksheet.write(0,0,Value) #写入数据,共3个参数,第一个参数表示行,从0开始,第二个参数表示列从0开始,第三个参数表示插入的数值
workbook.save('top250.xlsx') #写完记得一定要保存
我们完成了第二个作业:输出豆瓣top250电影名,一行一个后,就可以把获取到的数据存储到Excel了。
Python3作业二:输出豆瓣top250电影名,一行一个
在python3爬虫利器Xpath:用Xpath提取文本这篇文章中,我们学会了用Xpath来提取网页中的文本,输出的格式是这样的 那么如何一行一个的输出呢? 这需要...

# coding:utf-8
from lxml import etree
import requests
import xlwt
title=[]
def get_film_name(url):
html = requests.get(url).text #这里一般先打印一下html内容,看看是否有内容再继续。
#print(html)
s=etree.HTML(html) #将源码转化为能被XPath匹配的格式
filename =s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()') #返回为一列表
#print (filename)
title.extend(filename)
def get_all_film_name():
for i in range(0, 250, 25):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i)
get_film_name(url)
if '_main_':
myxls=xlwt.Workbook()
sheet1=myxls.add_sheet(u'top250',cell_overwrite_ok=True)
get_all_film_name()
for i in range(0,len(title)):
sheet1.write(i,0,i+1)
sheet1.write(i,1,title[i])
myxls.save('top250.xls')
输出结果如下:
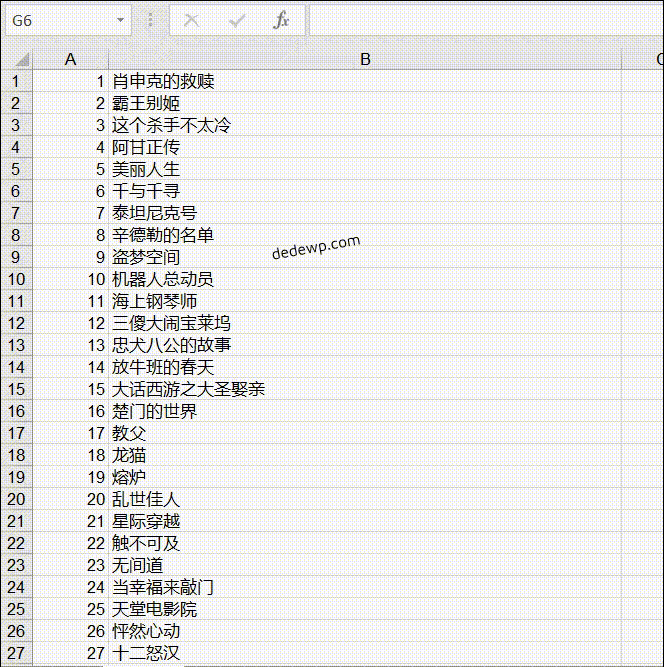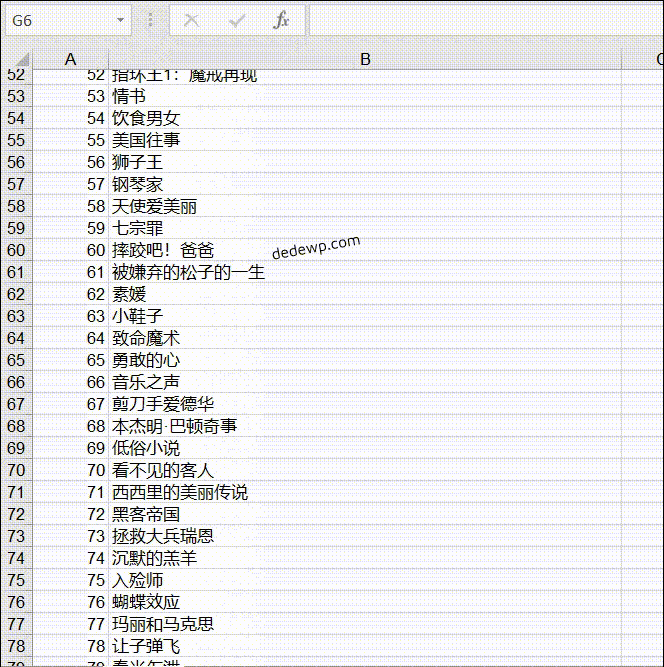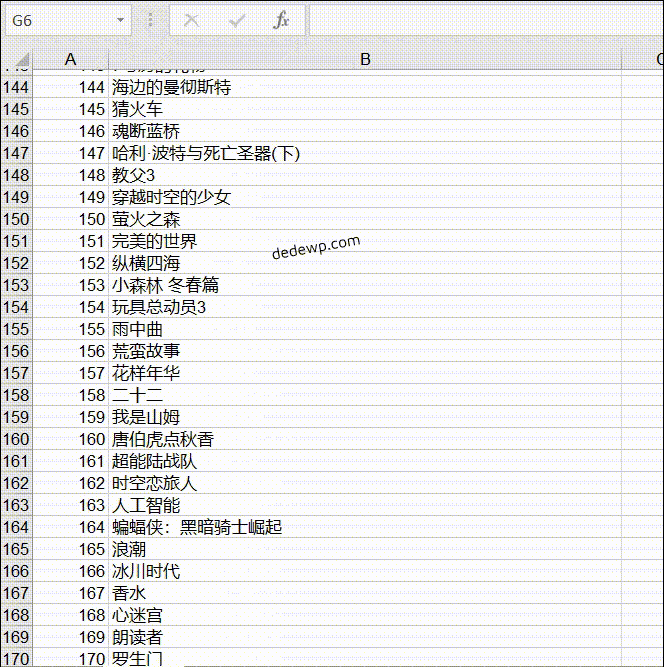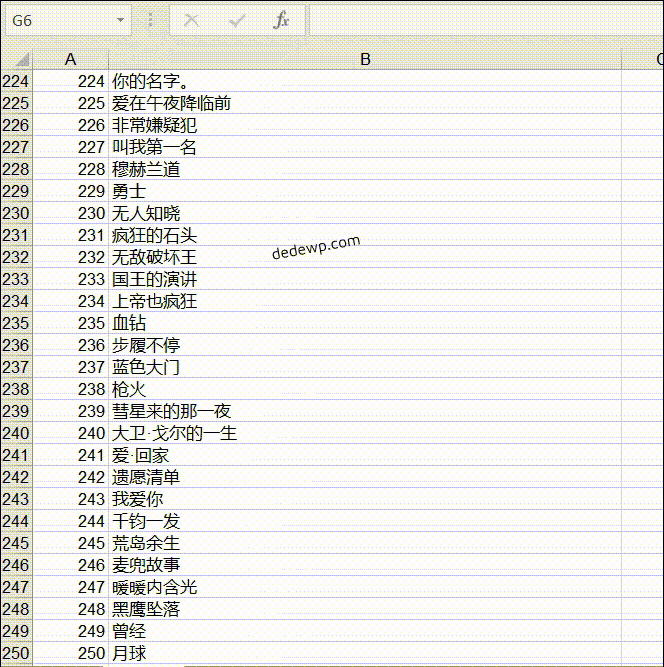
之前有小伙伴问如何将250个电影名全部输出来,实际上就是把网址根据规律循环一下就好了,可以参考上面的代码,还有就是列表的合并,这些基础知识在群文件的小白教程里都有介绍。
很多初学python的朋友,苦于找不到一群志同道合的朋友,小雨给大家提供了一个平台,一个纯粹学习python的交流平台,274728691 这是我的QQ号,也是python从入门到入魔的群号,欢迎加入。
加入须知:
Python3学习群重要通知,群友必看!
很多人进群后不及时提交作业,不珍惜这个学习的机会,陌小雨就设置一些门槛,特此申明如下(2018-3-14): 很多初学python的朋友,苦于找不到一群志同道合...